MAKING A SIMPLE DASHBOARD WITH HTMX
As I was wrapping up my academic work, I took on a quick side project to build a dashboard for monitoring server statuses in my lab. There used to be a similar tool created by a former lab member, but it had become outdated and was no longer maintained. My primary focus for this new dashboard was to make it: 1. simple 2. maintainable 3. modestly secure and 4. look nice.
Here is the final product (with some details redacted):
Home (Login)
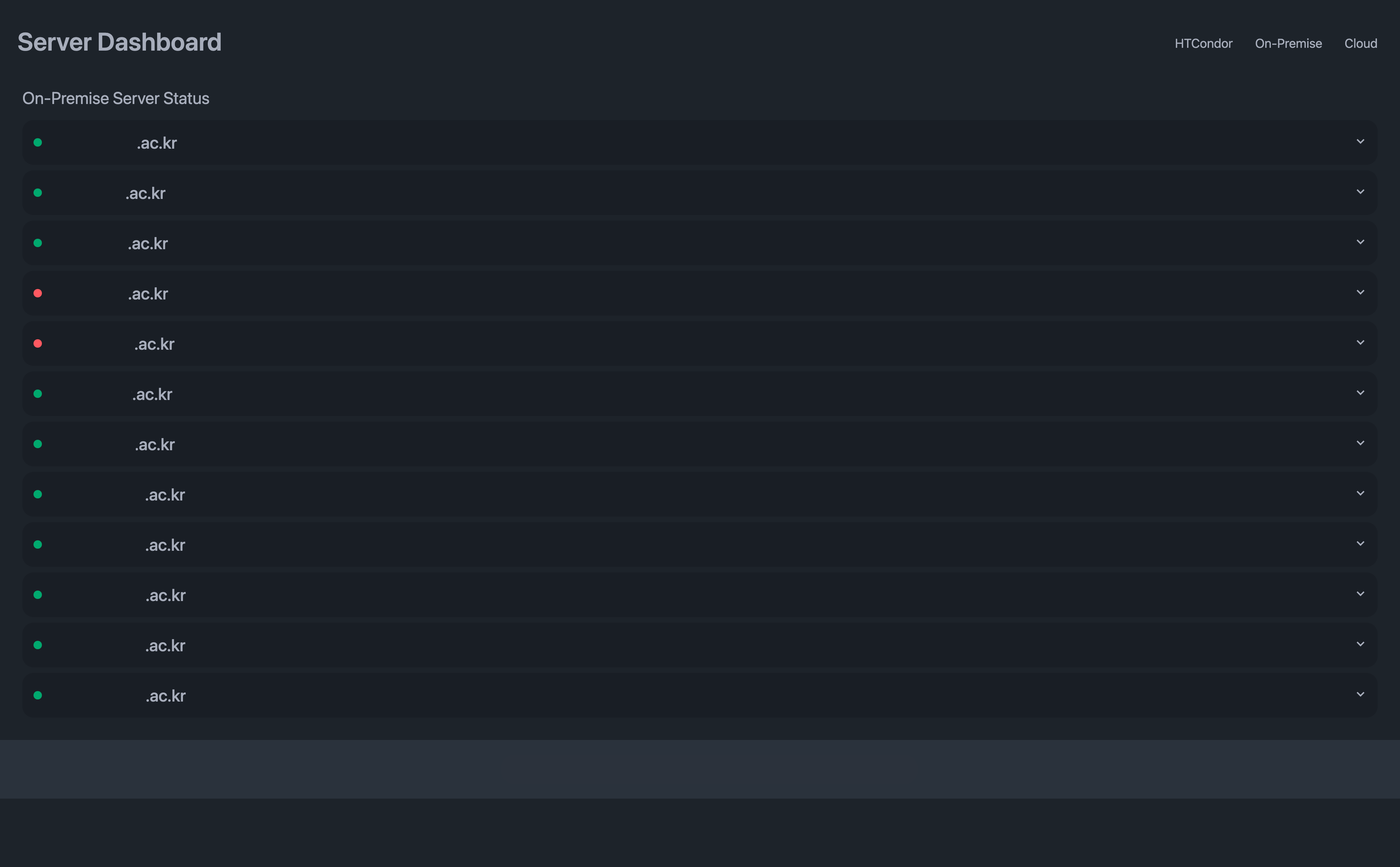
Dashboard
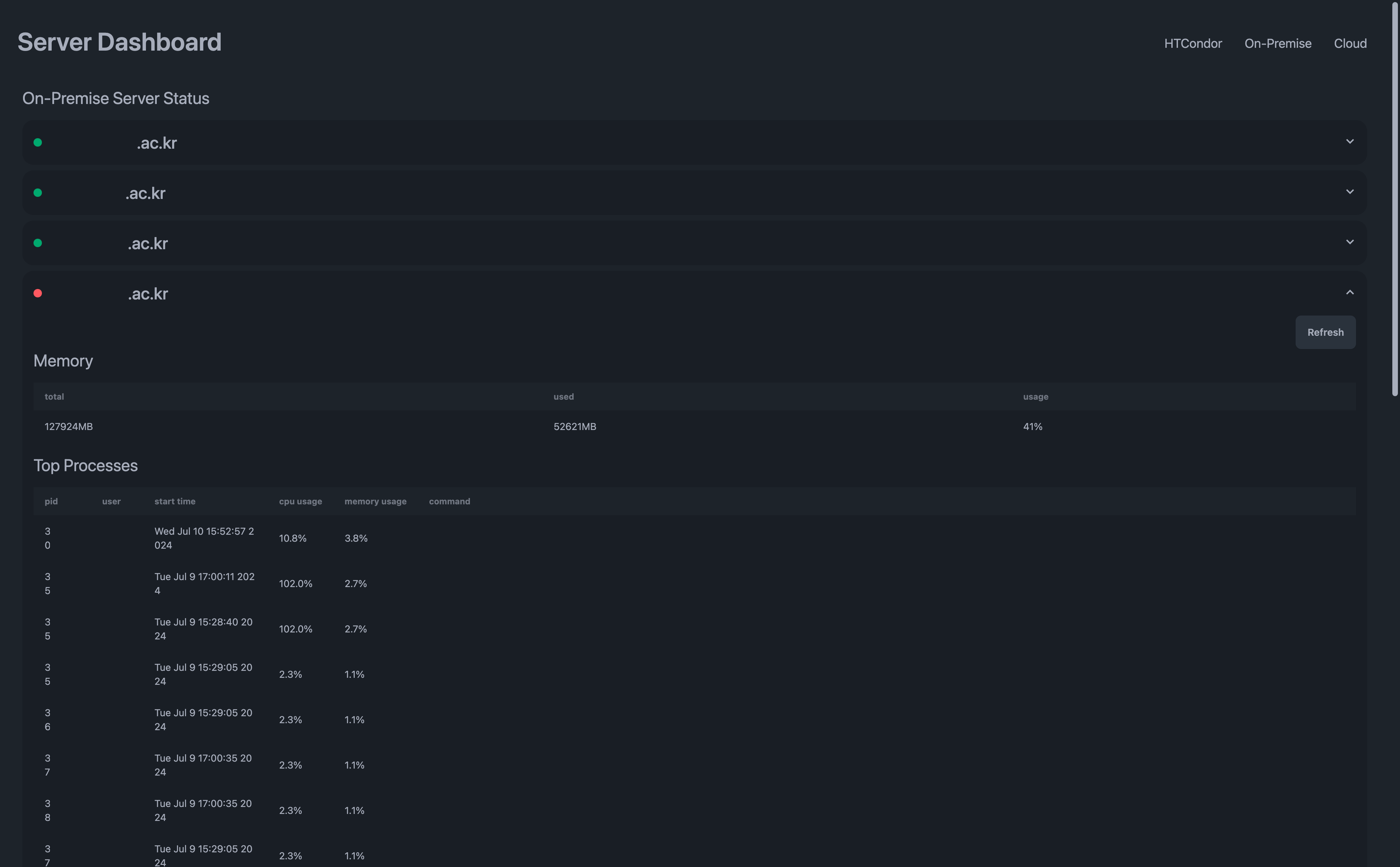
Dashboard with Details
Setup
Framework Choice
When choosing frameworks, I prioritized maintainability. Since most lab members were already familiar with Python but had no experience with popular frontend frameworks like React, I implemented the web server using FastAPI, a widely-used ASGI framework in Python.
For the user interface, I relied on vanilla HTML/CSS, Jinja templates, and DaisyUI1, a lightweight component library that enhances Tailwind CSS.
For interactivity, I opted for HTMX. If you’re unfamiliar with HTMX, check out my previous post. Since I avoided JavaScript runtimes, I included minified JS libraries for HTMX, Tailwind, and DaisyUI, along with their stylesheets, in the static folder.
Thankfully, FastAPI makes serving static files incredibly simple:
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")Templates
The HTML templates were powered by Jinja2 Fragments2, which allowed partial rendering of templates by targeting specific block names. This setup, combined with HTMX, made templates concise and easy to maintain. This makes for a concise template files for easier maintenance when coupled with HTMX.
For example, here’s a snippet from index.html with a content block:
<!-- index.html -->
<!-- some base template to inherit from -->
{% extends "base.html" %}
{% block content %}
<div class="flex flex-col gap-y-4">
<h1 class="text-2xl">On-Premise Server Status</h1>
{% set running = running | default([]) %}
{% if running | length > 0 %}
<div class="flex flex-col gap-y-2">
{% block on_premise_instances %}
{% for instance in running %}
{% with is_last = loop.last, name = instance.name %}
{% include 'on_premise/instance.html' %}
{% endwith %}
{% endfor %}
{% endblock %}
</div>
{% endif %}
<div id="page-indicator" class="htmx-indicator loading loading-bars loading-lg self-center"/>
</div>
{% endblock %}Depending on the route and request type, I could choose to return either the entire template or just parts of it. For instance:
- /on-premise: Returns the content block for HTMX requests or the full page otherwise.
- /on-premise/instances: Returns a partial block for lazy loading upon refresh.
Here’s how these routes are implemented:
# dependencies
# check_session: checks for valid session cookie. if session is invalid or has expired, move to login page
# is_htmx_request: check for `hx-request` header in the request
@app.get(
"/on-premise",
response_class=HTMLResponse,
dependencies=[Depends(check_session), Depends(is_htmx_request)],
)
async def on_premise_page(request: Request):
running_instances = await onpremise_service.get_server_infos(after=0, size=1)
# load all on-premise servers in background
return templates.TemplateResponse(
"index.html",
context={
"running": running_instances,
"request": request,
},
block_name="content" if request.is_htmx_request else None,
)
...
@app.get(
"/on-premise/instances",
response_class=HTMLResponse,
dependencies=[Depends(check_session)],
)
async def get_on_premise_instances(
request: Request, after: Optional[str], size: int = 1
):
running_instances = await onpremise_service.get_server_infos(
after=after, size=size
)
return templates.TemplateResponse(
"index.html",
context={
"running": running_instances,
"request": request,
},
block_name="on_premise_instances",
)Minor optimizations
To gather server information remotely, I used paramiko, a Python implementation of the SSHv2 protocol.
This approach is safer than executing commands with subprocess or similar tools.
Since commands like nvidia-smi (for GPU info) can be slow, I implemented lazy loading and pagination using HTMX. The hx-trigger="revealed" attribute in HTMX ensures that paginated endpoints are called only when the last loaded element is visible.
Here’s an example of lazy loading:
{% if is_last %}
<div class="collapse collapse-arrow bg-base-200" hx-get="/on-premise/instances?after={{ name }}&size=5" hx-trigger="revealed" hx-swap="afterend" hx-indicator="#page-indicator">
<input type="checkbox" name="{{ name }}"/>
<div class="collapse-title flex flex-row items-center gap-x-4">
{% if instance.usage == 0 %}
{% set status = 'success' %}
{% elif instance.usage < 50 %}
{% set status = 'warning' %}
{% else %}
{% set status = 'error' %}
{% endif %}
<div class="badge badge-{{ status }} badge-xs"></div>
<div class="text-2xl font-medium">
{{ instance.name }}
</div>
</div>
<div class="collapse-content overflow-x-auto">
<div class="flex justify-end">
<button class="btn btn-neutral btn-md" hx-get="/on-premise/instance/{{ name }}" hx-swap="innerHTML" hx-target="#{{ name }}-content" hx-indicator="#{{ name }}-indicator">
<span id="{{ name }}-indicator" class="htmx-indicator loading loading-dots loading-sm"></span>
Refresh
</button>
</div>
<div id="{{ name }}-content" class="flex flex-col gap-y-4">
{% include 'on_premise/instance_content.html' %}
</div>
</div>
</div>
{% else %}
<div class="collapse collapse-arrow bg-base-200">
<input type="checkbox" name="{{ name }}"/>
<div class="collapse-title flex flex-row items-center gap-x-4">
{% if instance.usage == 0 %}
{% set status = 'success' %}
{% elif instance.usage < 50 %}
{% set status = 'warning' %}
{% else %}
{% set status = 'error' %}
{% endif %}
<div class="badge badge-{{ status }} badge-xs"></div>
<div class="text-2xl font-medium">
{{ instance.name }}
</div>
</div>
<div class="collapse-content overflow-x-auto">
<div class="flex justify-end">
<button class="btn btn-neutral btn-md" hx-get="/on-premise/instance/{{ name }}" hx-swap="innerHTML" hx-target="#{{ name }}-content" hx-indicator="#{{ name }}-indicator">
<span id="{{ name }}-indicator" class="htmx-indicator loading loading-dots loading-sm"></span>
Refresh
</button>
</div>
<div id="{{ name }}-content" class="flex flex-col gap-y-4">
{% include 'on_premise/instance_content.html' %}
</div>
</div>
</div>
{% endif %}To speed things up further, I implemented a time-to-live cache for service methods (all written as async functions). For details, refer to my post on caching async functions.
Additionally, I created a simple session management service to ensure that only authorized users could access the dashboard.
Dockerize & Deploy
To ensure consistency and security, I containerized the application using Docker. I chose the lightweight slim-buster image as the base for Python:
FROM python:3.10.8-slim-buster
RUN apt-get update -y
WORKDIR /code
COPY requirements.txt /code
RUN pip install --upgrade -r /code/requirements.txt
COPY src /code
# launch entry script
ENTRYPOINT [ "python", "main.py" ]I also created a GitHub workflow to automate the release process:
name: Build Docker Image and Release
on:
push:
tags:
- '*.*.*'
jobs:
build-and-release:
runs-on: ubuntu-latest
env:
# bunch of secret variables
steps:
- name: Checkout repository
uses: actions/checkout@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Set dot env
run: |
echo "RANDOM_API_KEY=${RANDOM_API_KEY}" >> .env
mv .env src
- name: Build Docker image
run: |
docker build --platform linux/amd64 --tag dashboard:latest .
- name: Save Docker image to file
run: |
docker save -o release.tar.gz dashboard:latest
- name: Get release
id: get_release
uses: bruceadams/get-release@v1.3.2
env:
GITHUB_TOKEN: ${{ github.token }}
- name: Upload Docker image to Release
uses: actions/upload-release-asset@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
upload_url: ${{ steps.get_release.outputs.upload_url }}
asset_path: ./release.tar.gz
asset_name: release.tar.gz
asset_content_type: application/gzipThis project took less than a day to implement, thanks to the simplicity of FastAPI and HTMX. After some minor tweaks for mobile responsiveness, the dashboard was well-received by my lab members.
Hopefully, it will remain a valuable tool for the team.