CLIENT-SIDE SCRAPING WITH WEBVIEW - PART 1
Web scraping is perhaps the most common choice for a side project. While there are plethora of resources on web scraping on server-side, i.e. using a centralized server to crawl the web or a controlled web driver, there is almost no resource on client-side scraping or web automation at the client-side. In this post, we would like to focus our discussion on the client-side scraping and automation in applications.
Client-side scraping and automation is using client resources to scrape potentially third-party web or to automate client workflow. This provides several advantages over naive scraping, which often involves calling previously researched APIs or controlling a browser remotely with regression testing suite such as Selenium1:
-
It saves server resources by delegating compute required for centralized scraping and automation. From available information, RabbitOS relies on a similar idea and has a centralized server that hosts instances of client devices, which can be expensive as emulators / web drivers can take up a significant amount of resources.
-
It makes for a better user experience as clients do not require communication with the centralized scraping server.
-
It can (partially) avoid legal complications of scraping third-party web as it is the individual client devices doing the scraping. As for the automation, we are only improving user experience by automating what the clients are doing.
-
It provides a flexibility on designing user experiences and interface.
Using Webview to our advantage
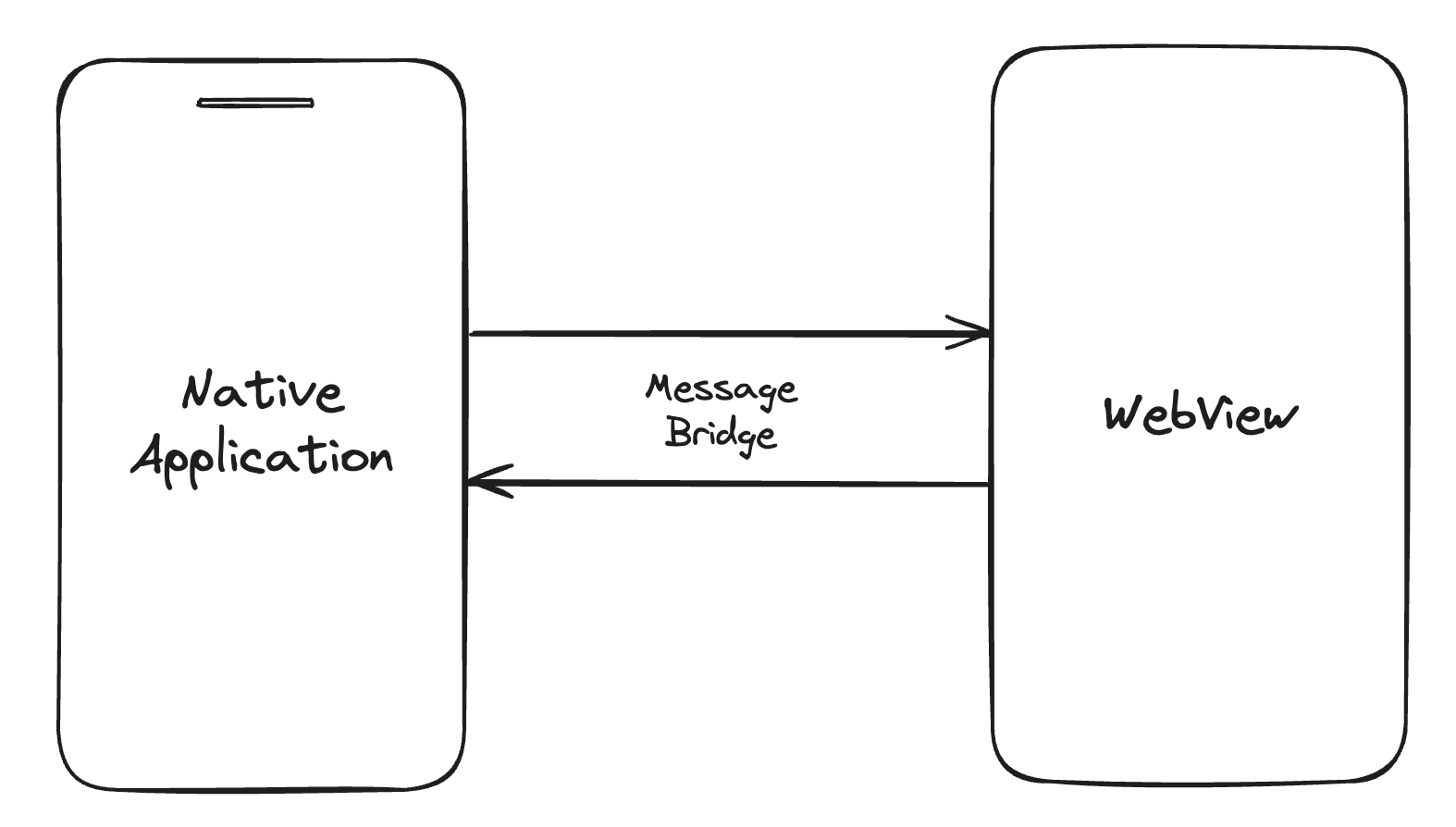
Many UI frameworks provide webview, an embedded web browser within an app. Since it is usually used for embedding web-based applications, it provides APIs that can bridge between itself and the native application for controlling the flow. We can use these APIs to our advantage as it provides a way to transfer data between the native application and webview.
Some use cases
Why do we need this? You may ask. There are potentially great use cases for this. In fact, this is already being used in many personalized finance apps that need to collect data from multiple banking websites, but has no public APIs to do so due to legal reasons. In order to implement this feature, you would need to
- Collect credentials from the native app input by the user
- Input the credentials in the respective website
- Parse the data from the webview then pass it back to the native app for various use cases, e.g. show it via common user interface or send it to the domain server for recommendation services
This enables simplified user interfaces and plenty of opportunities for additional features for a better user experience. Another use case would be a centralized search for a specific domain, for instance e-commerce. Given a query, we can leverage the personalized recommendation and search features already implemented in the respective platforms to show all the products within a single view for an easier comparison.
A more relevant use case nowadays would be coupled with large language models to summarize the outputs or translating natural language query to scraping requests (or function calls). If the language models gain capabilities to plan for itself (even though I highly doubt this would happen in a reasonable time frame and with the current direction in AI research), it would enable an autonomous agent to look for relevant information given a simple query, greatly reducing time and effort of users investing in these activities. However, this seems far considering the current capabilities of LLMs.
More details will be explained in the coming posts.